Naoko Ishibashi

Junior Data Analyst
Junior Data Analyst
Technical Skill: R, SQL, Java, Python, Tableau, Power BI
Education
-
B.A.A.S, University of Pennsylvania Data Analytics & Social Sciences (August 2024) -
A.S, Community College of Philadelphia Computer Science (May 2021)
Experience
Data Analyst and Programmer Intern @ Senior Grooming (August 2023)
- Analyzed demographic data with R to produce reports that supported strategic expansion.
- Programmed Java for API integrations with SendGrid to manage transactional emails.
- Developed custom email templates in SendGrid, improving user experience and ensuring brand consistency.
Certifications
- Introduction to Database and SQL, Great Learning (June 2024)
Project
Regression Analysis in Base R
Utilized regression analysis, multivariate regression, statistical, and probability analysis on 2020 US National Election Survey data to assess voter sentiment towards the Democratic Party. Applied sampling theory, cleaned data, and created concise visualizations to summarize findings.
- Skills: R, statistics, data visualization.
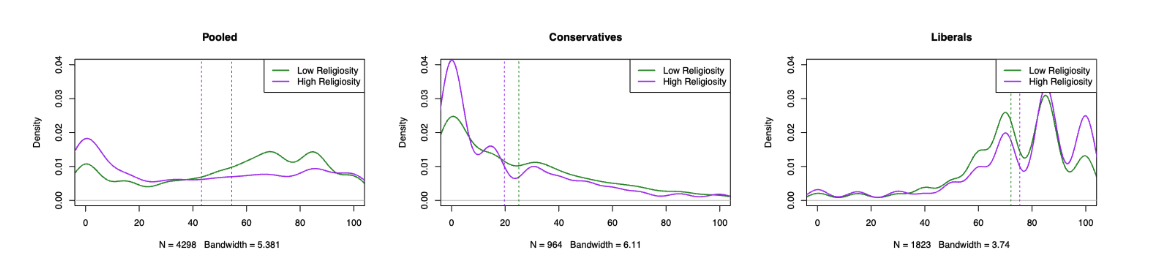
Diabetes Research Analysis
B-Cell Analysis Project Presentation
Analyzed 20,000 rows of data to examine the correlation between clone size and mutation in healthy and diabetic samples. Performed hypothesis testing to find significant results, indicating a notable increase in mean clone size in diabetic individuals. Created bar graphs to assess V-gene usage consistency across six donors, highlighting higher values in diabetes. This research suggests potential factors for risk prediction and prevention in Type 1 diabetes.
- Skills: R, statistics, hypothesis testing, data visualization.

R-Shiny
Developed a Shiny application with Leaflet widgets for Philadelphia schools and LEA datasets, focusing on attendance-based rankings. Utilized text analysis and integrated SQL within R for advanced geospatial analysis.
- Skills: R, Shiny, data visualization, UI/UX.
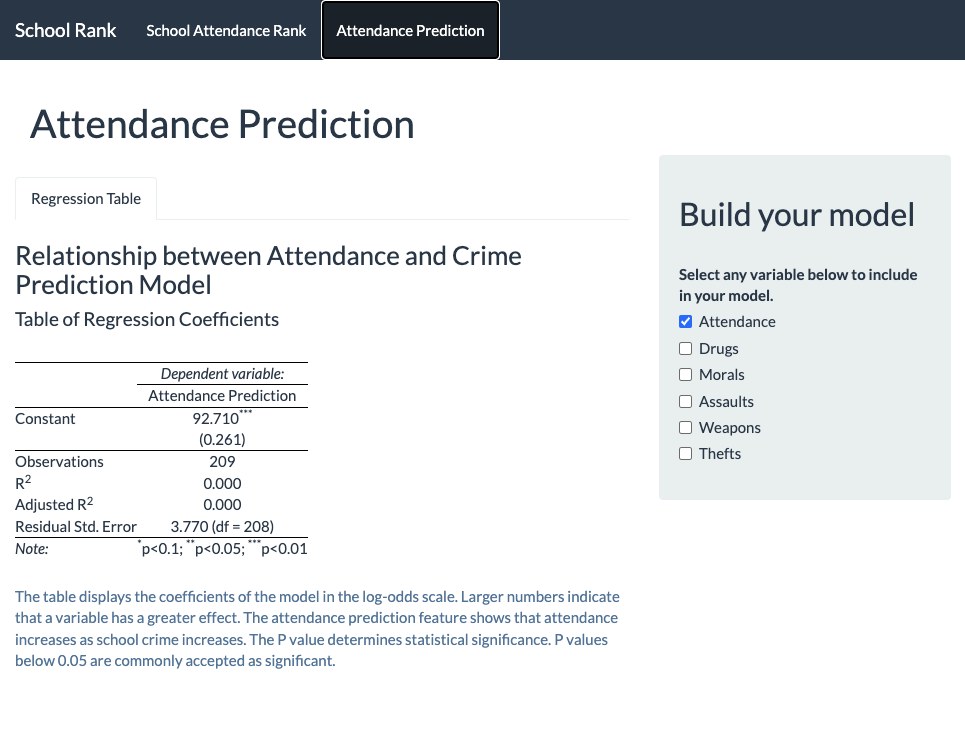
SQL Data Project
The analysis compares median annual salaries across companies of different sizes, finding that companies with around 1000 employees pay between $250,000 and $260,000, while larger mega-companies offer slightly higher median salaries of $268,000 to $275,000. This highlights a trend of increasing salaries with company size.
- Skills: SQL, database management, data transformation.

Hypothesis Testing and Estimators
Hypothesis testing in these regressions evaluates whether the independent variables (like education level or region) have a statistically significant impact on the dependent variables (like median income or commute behavior). It tests whether the observed relationships are due to chance, with the null hypothesis assuming no effect and the alternative suggesting a significant effect.
- Skills: Statistics, R, hypothesis testing.
Data Cleaning and Transformation
This project focuses on data cleaning and analysis using dplyr, including tasks like filtering non-cancelled flights, analyzing delay patterns, and identifying delay-prone carriers and destinations. A bonus task involves examining baseball batting averages while accounting for potential data biases.
- Skills: R, SQL, data wrangling, tidying datasets.
Random Variables
In this project, I conducted a series of statistical analyses and simulations using R. I calculated probabilities and confidence intervals for normal distributions, simulated dice rolls to explore probabilities related to Yahtzee, and analyzed coin flip data to estimate streak lengths. This work involved applying statistical techniques, such as normal CDFs and Monte Carlo simulations, to derive meaningful insights and visualize results through plots. The project demonstrates my proficiency in data analysis, statistical modeling, and simulation.
- Skills: R, statistical modeling, probability simulation, Monte Carlo methods, data visualization

Automotive Complaint Analysis
Subaru Quality Insight Project report Power BI dashboard
I built a 3-page Power BI dashboard to analyze over 3,500 vehicle complaints from 2019 to 2025. The goal was to spot trends, compare brands, and identify quality issues. Using Subaru as a case study, I found a complaint spike in 2024, especially in popular models like the Crosstrek and Forester. This project shows how data dashboards can help monitor product performance and support decision-making.
- Skills: Power BI, DAX, data cleaning, KPI tracking, data storytelling

GIS Analysis - Analyzing Age 65+ Population and Median Income
I analyzed senior population and income data across Philadelphia to identify ideal service areas for a grooming business. The report highlights key neighborhoods with high senior density and disposable income, using census data and geospatial visuals to support targeting strategy.
- Skills: GIS in R, census analysis, demographic mapping, report writing
